Case Study
University of Leeds Libraries: infrastructure project covering digital preservation through to public engagement

Early 20th century headband, made in China. International Textile Collection, ITC 2015.212, https://explore.library.leeds.ac.uk/special-collections-explore/665594. Image reproduced with the permission of Cultural Collections and Galleries, University of Leeds Libraries.
Introducing DLIP
The Digital Library Infrastructure Project (DLIP) is a 4 year major strategic initiative for the University of Leeds Libraries (UoL). This digital transformation project aims to improve access and increase usage of the Libraries’ cultural collections for teaching, research and wider public engagement.
In a familiar pattern, UoL has accumulated many fragmented approaches to storage, preservation processes, and delivery of digital objects. Digirati was appointed as technical partner to both design and implement a new standards-based infrastructure in close collaboration with the UoL DLIP team.
Key drivers behind the initiative included a recognition that the collections are increasingly born-digital or with a requirement to be digitised. Funding now often depends on the provision of digital methods to interact with and interrogate the collections, and future acquisitions also depend on the ability to both preserve and showcase them. Furthermore, UoL needs to increase the reach of both local and global audiences.
The guiding principle of the project was the adoption of open standards in order to maximise the potential for interoperability of collection items within the cultural heritage digital ecosystem, increasing outreach and impact. It also furthered UoL's desire to engage in a community of peers, increasing the opportunity for support, collaboration and raising the sustainability levels of their content and data beyond the lifetime of their systems, supporting long term preservation.
As a first step UoL put together a comprehensive business case which had been approved by the University to initiate the project. The extensive research and resulting objectives, principles and use cases from this work helped inform an initial design phase conducted by Digirati which resulted in a draft solution architecture and corresponding delivery plan both of which were then allowed to evolve over an iterative, collaborative implementation approach based on Agile principles.
You can read more about DLIP in the Leeds University Libraries Blog.
Digirati then embarked on sequences of use case gathering, workshops with stakeholders (especially the people who will be using the tools we build), prototyping, design documentation and outreach to UoL’s peers. This informed the choice of standards and how the infrastructure makes use of those standards.
Standards-driven technology choices for preservation, description and delivery
Until very recently, a completely open-standards-based approach to large-scale digital library infrastructure was not self-evident. While IIIF is the obvious (and really, the only) choice for publishing digital objects, standards at the other boundaries of the system are only now taking shape.
Digital Preservation needs to look after two types of content: digitised material, such as high resolution photographs of manuscripts, letters, maps and artworks; and born digital material, the increasing amount of archival content that starts life in a computer, such as emails, word processing documents and text files. Either way, it’s about more than simply storing the files securely. We need to package files into logical groups that make sense now and in the future, and then keep those groups coherent and safe, possibly through multiple versions.
These preserved digital objects usually have a corresponding record in a library catalogue, or item description in an archive, or an entry in a museum catalogue. These records are the descriptive (or semantic) metadata: what the item is about. The DLIP project has chosen Linked Art as a way of integrating the very different types of description from different sources to drive discovery, interrogation and exploration of the collections. Linked Art doesn’t replace the source descriptive metadata, but aggregates it into linked data for cross-collection discovery and insight.
IIIF is the obvious choice for the delivery of collections comprising images, audio, video and now 3D resources. They become part of an enormous linked digital ecosystem. This goes beyond simply getting digital objects onto web pages; while IIIF acts behind the scenes as the model behind the user experience on the web, it makes collections interoperable for research purposes, for both machine and human engagement, analysis and enrichment. IIIF the integration point for a collections-as-data approach. It also allows content to be reused and remixed, in exhibitions and teaching scenarios, using the growing number of tools built by Digirati and others.
Linked Art and IIIF are two of the three DLIP foundational standards. But digital preservation standards are more abstract. The Open Archival Information System (OAIS) is a reference model that digital preservation systems follow. It describes how they operate and how information flows in and out of them, but not at the same level of interoperability as IIIF or Linked Art. There are multiple ways of following the reference model (and what Digirati has done for DLIP is one of them).
We want to store the digital objects on disk (or in the Leeds case, in Amazon S3) in such a way that we can identify the boundary of each digital object – what files and folders are part of the object as opposed to parts of other objects or other file system organisation – and also preserve and understand the version history of the object, so we can clearly identify its current content but also access previous iterations of content. And we want to do this as efficiently as possible, and not duplicate unchanging files from version to version.
These needs are now met by the Oxford Common File Layout (OCFL), the third member of the trinity of open standards on which DLIP is based.
What OCFL gives us is the ability for someone in the future to reconstruct all our preserved digital objects, with their version history, from just the files. While we need digital preservation software to manage workflows, and databases to store information for quick retrieval and practical day-to-day operations, the preserved content as OCFL on disk is complete without them. And the systems we use on top of OCFL can be upgraded or replaced in the future without requiring changes to the preserved file layout.
Fedora as a Gateway to OCFL
For DLIP we are using the Fedora Repository as the layer between our business processes and the OCFL storage. The latest version of Fedora stores digital objects as OCFL, on disk or in our case in Amazon S3, meaning we can use Fedora’s well-established APIs to create and update our OCFL objects.
This leads us to our DLIP Solution Architecture (click here for PDF version):
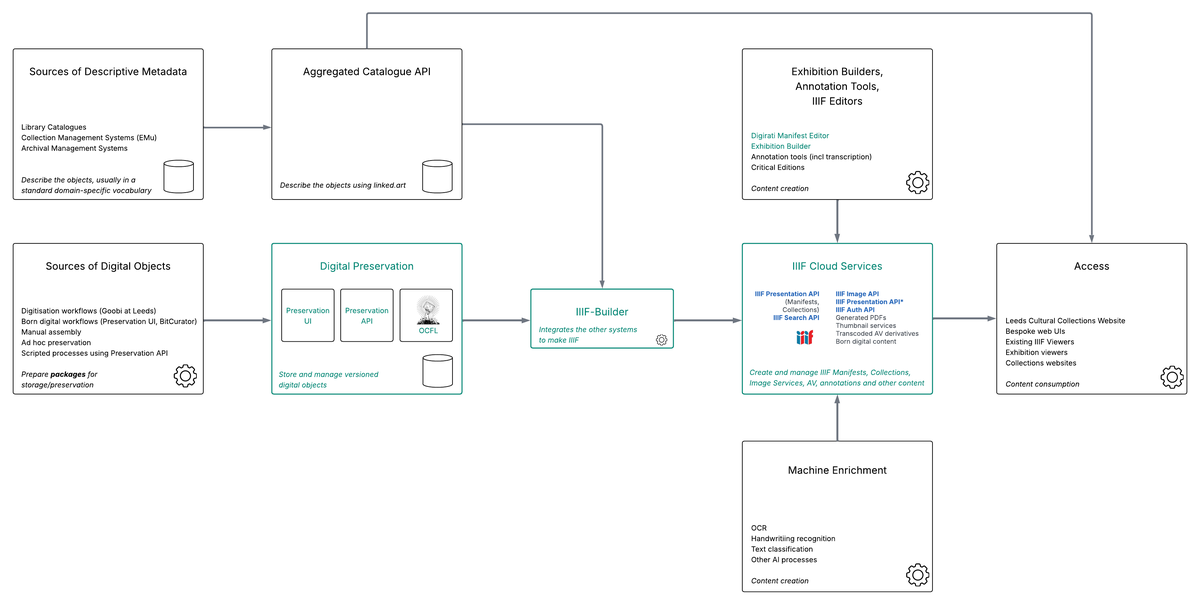 DLIP Solution Architecture
DLIP Solution Architecture
The parts in green are the core DLIP elements developed by Digirati. Other elements of the architecture are built by the Leeds team, or are third party integration points.
Digital Preservation
Fedora on its own is a repository, not a complete Digital Preservation solution. The specific use cases and workflows that DLIP requires are provided by three additional software layers – two service layers (APIs) and a user interface. We designed these to integrate with the IIIF content delivery provided by IIIF Cloud Services.
A more detailed technical explanation of the following sections can be found here.
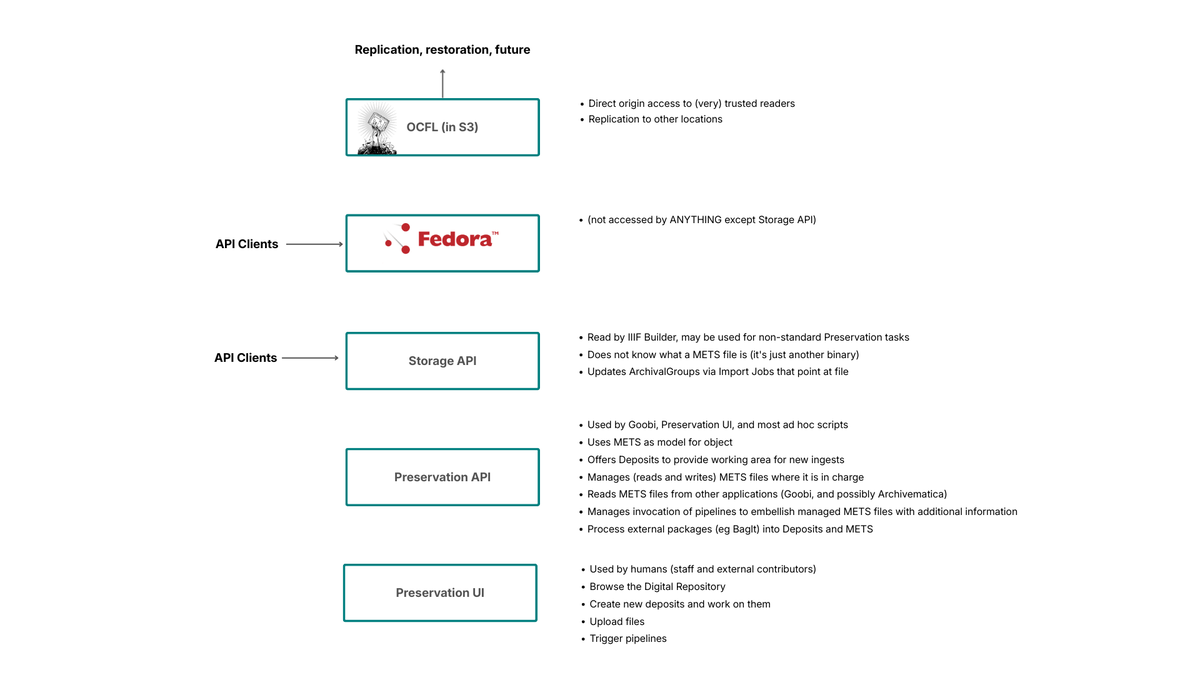 Digital Preservation Solution Overview
Digital Preservation Solution Overview
The Storage API
This is the only part of the system that talks to Fedora directly; it stores and manages the digital objects in the repository, translating Fedora and OCFL concepts into a simplified model. Any application that wishes to navigate the repository, and store or retrieve versioned objects, can use this API. On its own, it’s not sufficient to be considered digital preservation. It doesn’t have any opinion about what is being stored. Digital objects are created or updated via Import Jobs – a description of what needs to be added, deleted or edited to create a new (or new version of a) digital object. You send an Import Job to the API, and it processes it, ultimately resulting in a new OCFL object, or new version of an existing OCFL object, in storage. The Storage API implements the same Activity Stream mechanism as the IIIF Change Discovery specification to provide a feed of preservation events that other systems can read and react to.
The Preservation API
This part of the system is what most of the other integration points talk to. It understands what a METS file is, and can read METS files produced by multiple different third parties (e.g., Goobi, Archivematica, EPrints) and can also create and manage METS files to its own profile, for digital objects that it manages entirely. The features of the Preservation API make it a digital preservation system. Central to the Preservation API is the notion of a Deposit – a workspace for assembling and evaluating digital objects to be preserved. The Preservation API embodies workflow rules, and can understand the outputs of common digital preservation tools for functions like PRONOM file format identification or virus scanning. It can also invoke those tools on the contents of a Deposit, and integrate the tool outputs with METS files. The Preservation API also provides an Activity Stream, publishing events for every preservation activity that an external system might be interested in.
The Preservation UI
Many preservation tasks in DLIP will be accomplished by third party tools and services that call the Preservation API, without much human intervention. Sometimes, direct creation and viewing of objects in a user interface is required, where no other system is managing that object. The Preservation UI is that user interface, and is where ad hoc born digital archive items are created, as well as being a place where existing objects can be examined. The UI also allows manual assertion of rights statements and access conditions at arbitrary levels of granularity. This information is used later when (and if) an object is surfaced as IIIF; the access conditions asserted here determine who can see the IIIF representation (or different parts of it).
In the past, the modeling of digital objects (typically using METS) at the preservation, description or otherwise archival stage wasn’t necessarily connected with their eventual IIIF representation. IIIF Manifests are often constructed from METS files, which provide storage location, ordering and structure as well as the administrative metadata needed to enforce eventual access control. While this is still true in our Preservation API and UI (there is no dependency on IIIF, which might evolve through many versions over the century-scale of a preserved object), we can express a stored digital object as an ephemeral, throwaway IIIF representation so that we can take advantage of existing IIIF editing tools as part of the preservation process. For example, using a IIIF Range Editor to create logical structure. This is then reflected back into the long-term METS representation. This ephemeral METS could be used as the basis for a public IIIF version, but it doesn’t have to be - that could have different aims and is likely to be richer in additional metadata; it’s likely to be produced by a component that knows about more than digital preservation: IIIF-Builder.
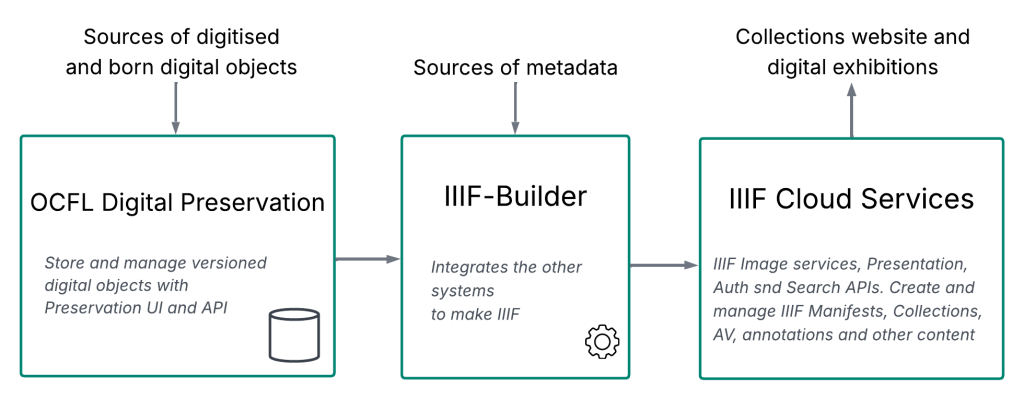
IIIF Builder
Digirati developed the initial version of this piece of middleware, and then the Leeds team have continued to develop it. It listens to events from the Preservation API Activity Stream, and creates or edits new IIIF resources in response.
Over the years Digirati has implemented many end-to-end digital delivery systems. It lets us see what’s common or commoditised through IIIF standards, and what is customer-specific.
Our design goal has been to make IIIF-Builder (the Leeds-specific part) as simple as possible by making the APIs either side of it (the Preservation API and the management APIs of IIIF Cloud Services) rich with features for the creation and management of IIIF Manifests and Collections. While it sits in the middle of the infrastructure, it could be considered part of user engagement, because it creates the IIIF resources that drive both user experience and machine interoperability. It decides on the “public face” of Leeds IIIF resources.
IIIF Cloud Services
IIIF Cloud Services is the platform that manages and serves the IIIF Manifests and grants selective access to content resources. It too has a user interface, which can be used to make ad-hoc Manifests for exhibitions and other purposes. But most of its content is created by IIIF Builder. It can read the source content resources from digital preservation, and provide web-friendly representations of them. For example, an image of a manuscript page might be preserved as a very large, high resolution TIFF file. This is no use on the web; IIIF Cloud Services publishes a IIIF Image API endpoint for that TIFF file, allowing deep zoom and other optimised web-friendly viewing. Another example is provision of transcoded, web friendly audio or video files rather than the archived source versions.
Standards and flexibility
The overall infrastructure is resilient and has components that can be changed in the future without requiring a complete overhaul. OCFL in storage is the best chance at recovery in the distant future, and IIIF driving the collections is the best way of encouraging outreach through interoperability.