Case Study
The Multimedia Yasna
A richly interactive film of a key Zoroastrian religious ritual drawing upon multiple sources of data.

The Multimedia Yasna is a wide-ranging project at the School of Oriental and African studies to explore the Yasna, the core ritual from the Zoroastrian religious tradition. The project concerts both the written text and the manuscripts containing this text and the performance of the ritual itself. For this part of the project, we were asked to produce a subtitled interactive film for the entire five hour Yasna ritual.
The interactive film drew upon multiple sources of data produced by the Multimedia Yasna team at the School of African Studies and their collaborators and partners elsewhere. These sources included:
- A high-resolution 5 hour film of the entire Yasna ritual and the preceding Paragnā
- An annotated transcript of the Avestan text of entire ritual produced using the ELAN annotation tool developed by the Max Planck Institute
- Corresponding ritual actions for each action in the film including translations from Middle Persian and Gujarati
- Machine generated object identification with bounding boxes for all of the objects in the video
- A comprehensive encyclopaedia of all of the objects identified in the film
- Visual designs in Figma
Digirati's task was to bring together all of this data in an easy to use interactive tool that allows uses to view the video, bounding boxes, encyclopaedia, transcripts and ritual actions in a single user interface.
Based on the initial visual designs and the data we knew that we had six main areas of user experience that we had to address:
- Video display
- Synchronise transcript with video
- Synchronise ritual actions with video
- Navigation to specific sections of the video in time, e.g. navigate to 23 minutes 11 seconds
- Navigation to specific sections of the video based on the structure of the Yasna ritual text, e.g. Yasna, Chapter 1, Stanza 1, Subsection 2.
- Display of encyclopaedia entries for the objects in the video
 Paused interactive video showing a selected object and encyclopaedia entry
Paused interactive video showing a selected object and encyclopaedia entry
To deliver this user experience there were three core technical challenges that needed to be met:
- Data integration: integrating multiple sources of information in diverse formats with different time granularity—some that change every frame, some change every few seconds, and some of which are static for long periods—into a single playable timeline that can be navigated by an end user
- Scale: the object tracking data has multiple bounding boxes per frame and many frames per second which for a 5 hour video—approximately half a million frames!—means that there many millions of bounding boxes and identifiers to work with
- Run time performance: the user experience should be smooth, seamless and fast irrespective of the size and complexity of the data
Our initial thinking was that we could, potentially, deliver a site driven from a combination of:
- A bespoke React client application
- Static JSON data for object tracking, transcripts and encyclopaedia entries
While the React application worked well, static JSON data was not suitable for driving the React client application largely for reasons of scale. The total number of eventual frame records (more on this below) was over 615,000. The end result would either have been a huge number of files or files of huge size, or both.
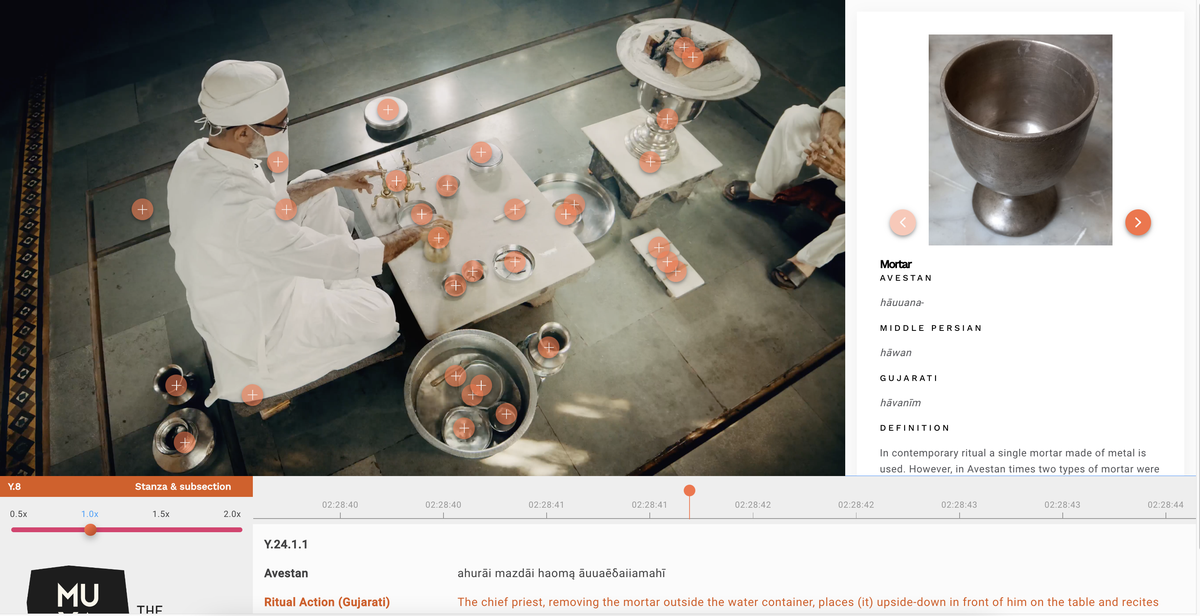 Interactive Yasna video paused to show object identification, transcript and ritual actions
Interactive Yasna video paused to show object identification, transcript and ritual actions
Click here to preview the Yasna interactive film
Our eventual solution was a combination of:
- A bespoke React client application
- A Django Rest Framework based backend application with APIs for serving:
- Per frame data that can be requested for any point in the video to return all of the bounding boxes, ritual actions and transcript text with precision down to tens of milliseconds
- Paged/streaming data for transcripts and ritual actions that can be continually updated/lazily loaded as the video plays
- A navigation API mapping the semantic structure of the Paragnā and Yasna to the underlying timeline of the video
Using a set of APIs allowed us to do all the heavy lifting of preparing and normalising the data on the backend in advance, effectively plotting all of the data for the 5 hours of the video on a unified virtual timeline with an API that accepts requests either using frame identifiers or timestamps to return all of the relevant data.
Whenever a user pauses the video or jumps to a different section in the timeline via the scrubber or structural navigation a simple API request with a lightweight JSON payload returns the data required to populate the annotations on the video, keeping the frontend application lightweight, fast and responsive.
Our virtual timeline was smart in the sense that we compressed the data, so that anywhere a single object or bounding box was static over multiple frames of the video, we stored a single point of data, rather than one for every frame, which meant that in areas where the video was relatively static at the level of an individual object we could economise on the amount of data we needed to store in our source data files—in this case, highly compressed Apache Avro files for speed and data storage efficiency—and the amount of data that needed to be stored in the backend for delivery to the client application.
More Case Studies